This is part one of a multi-part series. Continue with Part Two: From Keywords to Search Terms.
Google's Search ads might feel like a black box, but behind the curtain is really just a big pile of math. If you want to understand how search works today, we need to talk about what's been happening behind the scenes.
The year is 2010. Lady Gaga and Beyoncé are leaving their heads and their hearts on the dance floor, we started posting sepia-toned brunch photos on Instagram, and the Google homepage looked like this:
Fast forward 15 years. Lady Gaga is still making magic happen, Instagram is showing you everything but your friends' highly photogenic, sepia-toned lives, and the Google homepage looks like this:

Other than losing the ability to feel lucky (and gaining the ability to enter AI mode) it's not all that hard to feel like Search is mostly the same as it has always been. You drop some words in the search box and then Google does its thing and shows you a combination of ads and organic results that align with it.
That's the key — alignment. With Search, alignment isn't guesswork; it's an equation. Every search is converted from words to numbers. Those numbers are then weighed against the numbers that represent keywords in order to ultimately determine what results will show where.
While Google has always run on math, the math that powers the system has evolved steadily over the last 15 years, moving from crude word-counting to sophisticated models that capture meaning in context. Each step along the way has ultimately reshaped how and when ads appear.
To understand why campaigns behave the way they do today, we need to rewind. Think of this as a quick guided tour through the evolution of Search.
A Short(ish) History of Search
In the Beginning, There Was Frequency
At first, similarity was really just a measurement of frequency. If your keyword was "university" and one page used it three times while another used it 30 times, the latter page would be considered a stronger match. Clearly this system has some pretty glaring weaknesses (keyword stuffing and word order come to mind), but equally problematic was that meaning did not factor into determining similarity.
In this era, keywords like online MBA and MBA online would have been considered highly similar (because both have the exact same words) while college business masters and university MBA would have been highly dissimilar, as they have no words in common — even though they have very similar meaning.

In order for Search matching to be successful and effective, the math needed to be able to take into consideration not just word frequency but the nuance of relationships between words. Enter word embeddings.
Won't You Be My Neighbor?
The concept behind word embeddings comes down to proximity — that words that appear in the same context will literally appear within a window of neighboring words. With word embeddings, we are using math to predict how likely one word is to show up near another word and with this the similarity between words like college and university became easier to pick up on.

But static embeddings still had a major blind spot: polysemy — when a single word or phrase has multiple meanings.
Take the word program, for example. In higher ed, it refers to an academic track like an MBA program. In computing, however, it refers to software, or even the act of programming. Static embeddings ultimately blur these senses together, clustering "MBA program" too close to "computer programming."

The impact of polysemy is all the more magnified when a single word's meanings aren't just slightly different, but completely unrelated:
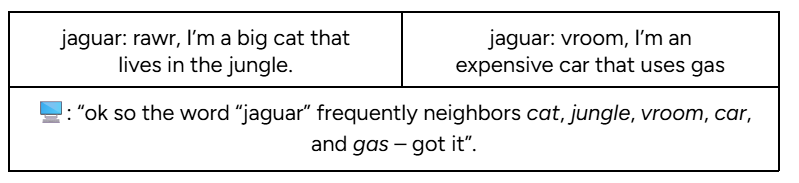
In order to enable intent-driven ad matching, the math needed to move beyond simple proximity. What was needed was a way to capture meaning in context — for the math to recognize and account for the difference between MBAs and software code, jungle cats and luxury cars. Without this, we don't have Google Search as it works today — and we definitely don't have broad matching.
As we approached 2020, this started to become possible.
Entering Our Sesame Street Era — Adding Context With ELMo and BERT
2017 and 2018 are when things start to get really interesting in the Natural Language Processing (NLP, or, "the way machine learning models handle text") world. In 2017, we get the publication of Attention is All You Need, a seminal article that introduces the concept of a Transformer. With Transformers, models no longer had to read text one word at a time, but instead could consider an entire block of text — and how each word in that text influenced the others — all at once.
In 2018, we got ELMo — Embeddings From Language Models. While ELMo doesn't use Transformers, it proved that bi-directionality — the ability to consider each word in a block of text and how it relates to its neighbours both left-to-right and right-to-left — could capture context in ways that static embeddings could never.
Then we get to 2019. This is where the game really changes. BERT — Bidirectional Encoder Representations From Transformers — steps on the scene and because this model uses self-attention, every word in a block of text can look at every other word in that block, all at once.


This model, which uses what's known as self-attention, changed the game and resulted in a situation where every word in a block of text could look at every other word in that block, all at once.
Essentially, if ELMo was a student reading an essay, they would be taking notes line-by-line and then trying to stitch them back together at the end to summarize the overall point. BERT, however, was scanning the entire essay, all at once, and seeing how the intro, thesis, and conclusion ultimately connect together into one cogent argument.
Or, if we're thinking about this from a Search ads perspective, with BERT, the algorithm is able to translate the entirety of a user's search into a mathematical equation that aims to encompass all of the words in that search and how they relate to each other when it comes to intent.
Cool Story, But What Does This Have to Do With My Ads In Market Right Now?
From counting words to capturing context, tracing the evolution of Google's algorithms explains how present-day Search is not simply matching strings of text. It's a mathematical equation that interprets meaning.
This history matters because it shapes every ad auction running today. What began as crude word-counting has become a system that can weigh intent, nuance, and context. That's how we arrived at today's Search landscape — and why ads can show up in places that might surprise you.
Ultimately, the most effective ways to use and optimize Search Ads has evolved in much the same ways as Natural Language Processing has. Many accounts (and their managers), however, are still stuck in the past, counting words and equating frequency with match strength. This mindset doesn't just miss opportunities; it risks wasting spend in an environment where context is everything.
The real question is: how do you optimize your campaigns in the contemporary Search landscape? In the next part, we'll leave the history behind and look at how this plays out in practice: search terms vs. keywords, and what that really means for broad, phrase, and exact match.
Continue reading: Part Two — From Keywords to Search Terms
All examples are drawn from anonymized or representative higher-education campaign data and do not reflect any individual institution’s performance.