This is a companion piece to my ongoing work analyzing RFI emails. If you've seen the headline numbers — the average quality ratings, the thematic breakdowns — this is the part that comes before all of that: how I decided the numbers were worth reporting in the first place.
"I used AI to analyze the emails" and "I can trust what AI is telling me about these emails" are two very different sentences.
The first describes a tool I used. The second describes an outcome that had to be earned, not assumed — and it's the distance between the two where the bulk of the work for this layer of my RFI project actually lived.
I'd also argue it's the topic most discussions of AI-supported work in higher ed skip right on over. For me, it's not enough to say "no, trust me — I tested this. Everything about how I've used AI is perfect and these findings are totally legit." While not everyone will want to read a piece about how I arrived at that conclusion, having that piece available to those who do is my attempt to practice what I preach and provide transparency, not a black box.
So here we go. Consider this the prologue to the findings — the part where I experimented and made sure the findings were real.
Why Use an LLM at All?
Let me start with the honest, unglamorous reason I reached for generative AI: I'm one person, and content analysis done by hand is brutally slow. I've been there, I've done that (and if you ever want a way-back playback, my master's thesis on corporate nationalism and the production of Sidney Crosby pre-dates the AI boom and, can confirm, represents countless hours of time-consuming media analysis done entirely by my own hand).
But back to this project. I knew I could pull together a lot of analysis about prospective student emails using contemporary tools made for the quantitative analysis of textual data. I also recognized that if I wanted to set myself up to be able to do content analysis and have a foundation for qualitative approaches to complement and contextualize the quantitative data, I was going to need more than that.
This year's iteration of the project includes classifications, ratings, and summaries for every single one of the nearly 8,000 emails I've received after submitting RFI forms. Realistically, reading each one and assigning a consistent set of topic, tone, sales-intensity, and quality judgments isn't just a weekend task — it would be a full-time job that would take months. Not only that, but by the end, the standards by which I was rating and ranking email #7,000 would inevitably have quietly drifted from what I had been thinking and feeling on email #100. That drift is the enemy of any content analysis that relies on being able to reliably compare one email to another.
Using an LLM offered a way around both problems at once: speed, obviously, but also consistency. The LLM interprets the prompt the same way, every time. It doesn't get tired. It doesn't get hangry. It doesn't care if it reads 35 similar emails in a row. In principle, that's not just a shortcut; it's a genuine methodological advantage.
Notice I said "in principle". That's because while an LLM can do this work, there's a lot of pre-work that needs to be done before confidently setting AI loose on 8,000 emails. And even when you've done that pre-work, there are some limitations and caveats you have to keep in mind when leveraging the output.
The Question Underneath the Question
Here's the thing about deciding to use AI for a research task: it quietly smuggles in a second decision you might not notice you're making.
The first decision is "I'll use an LLM." The second — the one hiding underneath — is "I'll believe what it gives me." That second decision should not be a given. And if you can't get that second one to a yes, then it really doesn't matter how much time the model will save you. A fast answer you can't trust isn't a shortcut; it's a liability with good production values.
So before I could even start to analyze any of the output from the classifications and ratings, the AI-generated portion of this project had its own research question to clear: can an LLM actually analyze the content of RFI emails well enough to rely on its results?
I didn't assume the answer was yes. I want to be precise about what "not assuming" looked like in practice, because "I tested it" is the kind of phrase people say to wave away exactly the scrutiny it should invite. So here's what testing actually meant.
Building the Prompts (and Watching Them Break)
I started small and familiar. My first test emails came from Worcester State University — a school I was familiar with from my time working there, with the added bonus that emails I had personally written were still in use today. Starting with content I knew intimately was deliberate: if the model misread an email I wrote myself, I'd catch it instantly, because I knew that original content so well.
From there I widened the aperture in stages — from a handful of schools with progressively larger sets of emails, then to a random sample of 1,000 emails from the full dataset. Each expansion was a chance for the prompts to encounter something they hadn't seen and fail in a new way.
I also worked my way up when it comes to how much direction I was giving the model. I began with zero-shot prompting — where the model only receives instructions and no example responses — in order to see what kind of output I'd receive. From there, I moved to one-shot (one example), and then to multi-shot (multiple examples). The output got better at every step, showcasing something simple but important: this type of task is hard to specify in the abstract, and that means the model learns more from being shown rather than just being told. This also means that instead of only needing to test your instructions, you need to test your examples, too, and find your way to a balance between adequate guidance and over-prescription.
From Prompt to Prompts
Testing not only surfaced the need for multiple examples; it also demonstrated that I needed multiple prompts. My first attempts began with a single prompt that tried to do everything: classify the topic and tone, rate the quality, and summarize the content — all in one pass.
Analyze the following college recruitment emails sent to prospective undergraduate students who have requested more information via an online Request For Information (RFI) form. For each email, extract key content and tone details and respond using the format below:
- Primary Topic: (such as: academics, student life, financial aid, visit, application)
- Tone: (for example: enthusiastic, formal, personal, generic)
- Sales Intensity: (rank as low, medium or high)
- Email Summary: (a brief, 1–2 sentence summary of the email's content. After summarizing, give it a quality rating between 1 and 5 and indicate why this rating was given).
- Call to Action (CTA): (describe the main call to action. After describing, give it a quality rating between 1 and 5 and indicate why this rating was given.)
Do not make assumptions. If a detail is not present, write "none".
The original, single prompt.
It became clear pretty quickly that the kinds of examples that taught the model to classify well were not the same examples that taught it to summarize and rate well. Optimizing for one degraded the other. This led me to split the work into two prompts: one for classification tasks, and one for summaries and ratings — each one tuned to its specific job.
The split also clarified what each set of examples needed to do. For classification, the examples needed to teach the model to recognize categories. I landed on six examples chosen to show the model different types of email — a deadline-driven application push, a campus-visit invitation, a student-life roundup — so it could see the range of what it would be sorting. For summary and ratings, they needed to teach the model to recognize quality. In this prompt, I ultimately used seven examples, to help teach the model about the types of characteristics that would pull ratings up or down on the five-point scale.
With certain models the user has control over the temperature setting, which governs how much randomness, or "creativity", the model can inject into its responses. A low setting means similar inputs produce similar outputs, which is exactly what you want when your entire analysis rests on comparable, repeatable judgments. For this type of task, creativity was a liability. I wanted the boring, reproducible answer every time. I set the temperature to 0.1.
Consistent ≠ Unbiased
There's an important subjectivity that's frequently overlooked in this kind of work. Knowing this, I want to purposefully pause for a moment here, sit with it, and talk through it rather than pretending it isn't there.
Much of the testing I've outlined was undertaken with the goal of ensuring consistency — the same prompts, applied the same way, producing repeatable judgments. That's real, and it's necessary when leveraging AI for this type of work. But consistency only means the model is steady. It does not mean that the model and its outputs are not subjective.
This work is calibrated, but it's calibrated in a very specific fashion. That calibration comes from two sources of implicit bias. First, there's the data that the LLM was trained on. These models are trained on a giant pile of human writing, and that writing reflects the cultures that produced it, including all of its assumptions, blind spots, and its sense of what "good" is. The model inevitably absorbs all of that — even the pieces we'd rather it didn't.
The second source is me. The way I wrote both the prompts and the examples are reflective of how I think about marketing, enrollment, and the prospective student journey. Every example, every category, every word reflects choices I made about how I see this work, and in turn nudged the model toward seeing the data in a particular way. I'm not a neutral party here. I shaped the lens.
Email Summary: This email emphasizes an urgent deadline for [the school's] priority review session. It repeatedly encourages the student to apply immediately, highlighting no application fee, optional test scores, and automatic scholarship consideration.
Quality Rating: 2
QR Explanation: The email is clear and action-oriented, but it focuses heavily on institutional urgency rather than student value. It repeats the deadline without providing compelling or personalized reasons for a student to apply.
Strengths: Clear deadline and next steps; provides some logistical benefits (no letters of recommendation, no test scores, quick decision)
Weaknesses: Overwhelming repetition of the midnight deadline; lacks emotional or motivational appeal; minimal effort to connect with the student's interests, goals, or aspirations
Excerpts from one of the rating and summary examples provided to the model.
I don't say this to undercut the project — I say it because it's true, and because it's exactly the kind of thing that goes unsaid when people talk about using AI for analysis. "The model was consistent" gets offered as if consistency can remove subjectivity. It doesn't. That lack of subjectivity doesn't mean we need to abandon the use of LLMs; what it does mean is that we need to stay aware of the conditions that have led to the generation of our results. The output is a perspective to interrogate, not an infallible measurement.
When the Words You Choose Change What the Model Sees
If you've read my earlier work on word sense — how the same word does different jobs depending on the context around it — this next finding is going to feel like that idea boomeranging back at me from inside my own methodology.
When I built the tone classifier, I gave the model a list of tone options to choose from. In an early version of the prompt, "urgent" was not on that list. In a later version, I added it.
That single addition moved urgency classifications up by 8.9 percentage points — the largest shift of any change I made between testing and final results.

An example of small changes to a prompt that ultimately catalyze substantial changes in the output.
And the increase didn't come from nowhere. It came almost exactly out of "enthusiastic," "personal," and "persistent" — three categories that each shrank by roughly the amount "urgent" grew. The emails hadn't changed. The model hadn't changed. The word I offered it had changed, and that was enough to reclassify hundreds of emails.
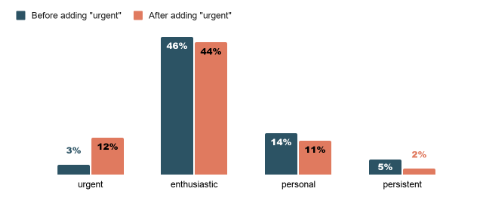
How tone shifted once the prompt included "urgent" as an example.
Sit with that for a second, because it cuts both ways. On one hand, it's a little unsettling: it means the categories I hand the model partly determine what it "sees." On the other hand, it's reassuring in a deeper way — adding "urgent" didn't scatter classifications randomly; it pulled them coherently out of the three tones that are urgency's closest neighbors. The model was behaving sensibly. It was telling me that a lot of emails I'd have called "persistent" are really better described as "urgent," and it only had the vocabulary to say so once I gave it the word.
Either way, the lesson here is an echo of what I've written about before: words matter. The prompt isn't a neutral pipe that data flows through. It's an instrument, and how you build it shapes what comes out the other end.
The Fitchburg State Problem
By the time I ran the prompts on the full dataset, they had gone through multiple rounds of testing. That's necessary to ensure the combination of model and prompts is working as expected. It doesn't, however, negate the need to validate your data.
When I was looking through the full dataset, I noticed something odd in the summary output. Fitchburg State University was everywhere. Dozens of emails had a summary with some variation of "The email from Fitchburg State University encourages Addison to apply by highlighting waived application requirements..."
Two things were wrong with this. Not only were these summaries oddly repetitive, the math wasn't mathing. I double-checked how many emails Fitchburg State had actually sent me — 35 — and yet far more summaries invoked their name.
So I did some digging to figure out what was actually going on. It turned out that none of the emails with Fitchburg State summaries had come from them at all — they were from Salem State, Iowa, Nevada State, Worcester Polytechnic, and a scattering of others. It was only when I pulled up the underlying text for each one that I found the real source of the problem: the email content had been pushed through blank.
Faced with nothing to summarize, the model did not say "this email is empty." It invented a plausible-sounding enrollment email — waived fees, priority scholarships, internship opportunities — and confidently attributed it to Fitchburg State University. Over and over. For emails that had no text and weren't from Fitchburg State.
| Summary | Count |
|---|---|
| The email from Fitchburg State University encourages Addison to apply by highlighting waived application requirements, priority scholarship consideration, and internship opportunities, while emphasizing the urgency to submit the application. | 19 |
| The email from Fitchburg State University encourages Addison to apply by highlighting waived application requirements, priority scholarship consideration, and internship opportunities. | 17 |
| The email from Fitchburg State University encourages Addison to apply by highlighting waived application requirements, priority scholarship consideration, and internship opportunities, while also mentioning the option to use the Common App. | 13 |
| The email from Fitchburg State University encourages Addison to apply by highlighting waived application requirements, priority scholarship consideration, and internship opportunities, while also offering a choice between their application and the Common App. | 7 |
The four most common hallucination variations (56 of 108 total); the remainder were minor rephrasings.
This is a hallucination in the textbook sense: the model generating content with no basis in the input, presented with the same fluent confidence as its accurate work. They read like perfectly ordinary enrollment email summaries. The only reason I caught it was that the volume tripped an arithmetic alarm: too many summaries for too few emails. The error didn't look like an error. It looked like data.
I ultimately removed all 108 of the affected results, and for future runs I'll strip empty emails out of the dataset before they ever reach the model. But the deeper takeaway isn't the fix. It's this: I had tested the prompts. I had iterated on the examples. I had done the up-front work well — and the output still contained a confident fabrication that only careful validation caught. You can try to head off hallucinations with clauses in your prompts, but those clauses aren't guarantees. Good prompting reduces errors. It does not eliminate the need to check.
So, Can an LLM Do This?
Yes — with an asterisk I'm happy to defend.
After all the testing, all the iteration, and a full pass of validating and auditing the output, I'm confident the model can classify, rate, and summarize these emails well enough to build real analysis on top of. When I audited the emails it scored highest and lowest, its judgments held up — the 5s were genuinely strong emails, the 1s were genuinely thin ones, and I found very little I wanted to argue with. That's not nothing. That's the model earning the trust I was unwilling to extend on faith.
But the asterisk is the whole point of this piece. The ratings are useful precisely because I treat them as a starting point for inquiry rather than a verdict to defend. They're a guide that tells me where to look more closely — not a final answer that ends the looking. Shifting from one prompt to two, prompt sensitivity driven by changing a single word, and the Fitchburg State hallucinations: none of those are reasons to distrust the project. The messy work in between "I used AI" and "I validated my use of AI" is what ultimately makes this project trustworthy.
Using a tool takes a moment. Trusting what the tool produces is a conclusion that needs to be earned over time — especially when the output can be confidently wrong in ways that look exactly like being right. The testing, auditing, and unglamorous afternoon spent wondering why one school's name won't stop showing up aren't the cost of doing this work honestly. They are the work.
So when someone tells you they used AI, let it invite a question — not whether they used it, but what they did to find out if they should believe it. It's the question I'd want asked of me. It's the one this whole piece exists to answer.